Difference between Ours and Domain Randomization
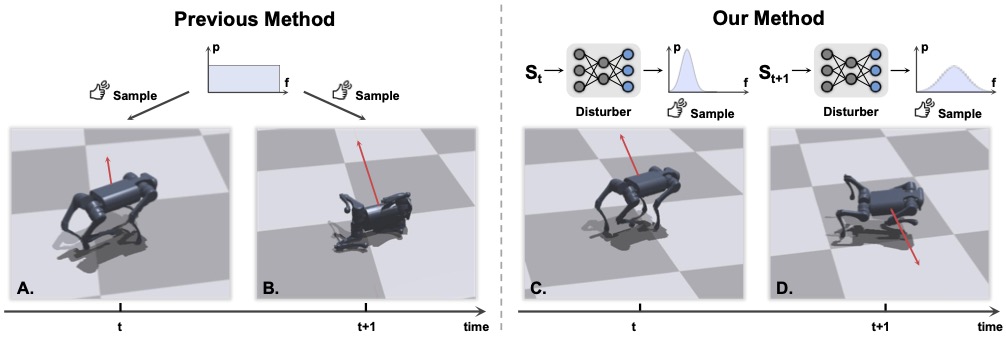
In traditional methods, the external forces are drawn from a fixed uniform distribution throughout the whole training process, which is less effective as
the disturbance can not adapt to the weakness of the behavior policy.
Framework Pipeline

Overview of H-infinity locomotion control framework. The blue box indicates a trainable module, the light yellow box is the loss function to optimize
these modules, and the green box indicates the data collected for training. At every time step during the training process, the current observation
is fed into both the actor and disturber. We perform a simulation step based on the robot's action and the external force generated by the disturber.
The current task reward is derived based upon transition, and our double-head critic outputs estimation for both task value and also overall value.
During the optimization process, we perform policy gradient on the disturber to learn proper forces based on the current performance of behavior policy,
and carry out H-infinity policy gradient by optimizing the PPO loss of the actor while taking into consideration the novel H-infinity constraint.
which we introduce to stabilize the training procedure. We adopt a dual gradient descent approach to address this constrained policy optimization problem.